中文
eBPF 用户空间虚拟机实现相关
续上一篇BPF笔记,这次记录一些实践相关的内容。不再区分classical BPF和eBPF,统称BPF。
开发板相关的内容在另一篇笔记。
Linux 内核相关
Linux 内核中的 BPF 实现有两个项目,分别都只有一条独立的master分支(避免维护时 rebase 起来混乱),bpf 分支和 bpf-next 分支。类似于 net 分支和 net-next 分支,bpf 分支是较为固定的,用来做些修补工作;bpf-next 是用来开发一些之后的 feature,或者做改进用的分支。源码在/kernel/bpf 下。
文档在 /Documentation/bpf/btf.rst 。
/include/uapi/linux/bpf_common.h 和 /include/uapi/linux/bpf.h 定义了指令集。
/samples/bpf 是一些 bpf 相关的样例(开发时的测试代码不应该放在这个目录下,因为逻辑可能比一般的样例复杂,需要测试边界情况),
/tools/bpf/bpftool 下面放一些用户空间用来 debug ebpf 程序的工具。
/tools/testing/selftests/bpf 下是测试代码。
对 BPF 指令的测试写在 /lib/test_bpf.c 和 /lib/test_verifier.c 中。
测试 BPF(相关文档为 /Documentation/dev-tools/kselftest.rst ):
bash
cd tools/testing/selftests/bpf/
make
sudo ./test_verifier
# This will generate `Summary: 418 PASSED, 0 FAILED`
# to run all of the tests
sudo make run_tests
llc --version 查看 LLVM 是否支持 BPF:查看输出的 Registered Targets。
llc -march bpf -mcpu=help 可以用来查看和设置支持的 BPF 指令集。
使用 clang 前端编译 C 代码 test.c 到中间 BPF 代码 test.o:
bash
clang -target bpf -c test.c -o test.o
用 readelf 去读test.o:
bash
readelf -a test.o
在内核中,BPF 相关的调用都是通过一个核心的系统调用 bpf() 来执行的,例如加载程序到内核、管理 BPF maps、管理 map entries、程序和 map 的持久化(通过 Pinning 实现)等操作。
在内核中的具体流程如下:
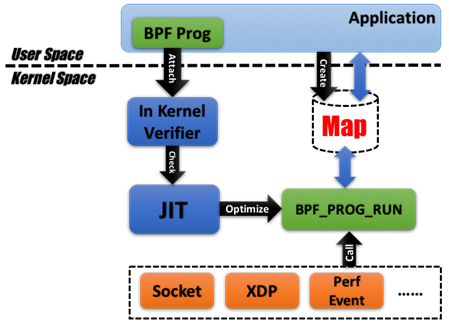
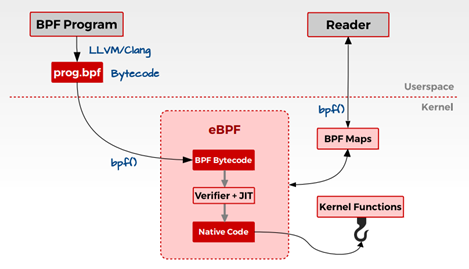
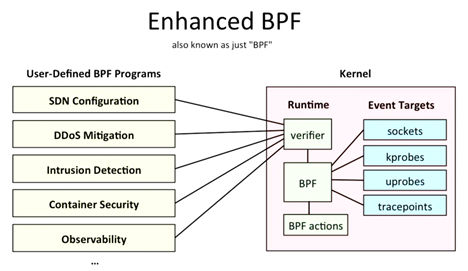
BPF 在内核中的执行都是事件驱动的,例如:
- 挂载了 BPF 程序的网络设备将会在它接收到包的时候执行程序
- 内核地址上挂载了 BPF 程序的 kprobe 时,只要该地址的程序执行了,就会触发 kprobe 的回调函数,接着触发 BPF 程序
示意图如下:
BPF 指令集
这部分翻译自 uBPF 的文档,它是上面提到的一个 BPF JIT Complier 的实现。
BPF 使用了 11 个 64位寄存器,32位称为半寄存器(subregister)和一个程序计数器(program counter),一个大小为 512 字节的 BPF 栈。寄存器以 r0 - r10 命名,r0 - r9 是指令可以使用的寄存器。默认情况下,运行模式是 64 位的。
BPF 程序指令都是64位的,假设 BPF 虚拟机指令集的编码顺序和宿主机的顺序相同,于是在下面的描述中不关心大端小端的问题。
所有的 BPF 指令都有着相同的编码方式:
msb lsb
+------------------------+----------------+----+----+--------+
|immediate |offset |src |dst |opcode |
+------------------------+----------------+----+----+--------+
从最低位到最高位分别是:
- 8 位的 opcode,有 BPF_X 类型的基于寄存器的指令,也有 BPF_K 类型的基于立即数的指令
- 4 位的目标寄存器 (dst)
- 4 位的原始寄存器 (src)
- 16 位的偏移(有符号),是相对于栈、映射值(map values)、数据包(packet data)等的相对偏移量
- 32 位的立即数 (imm)(有符号)
大多数指令都不会使用所有的域,未被使用的部分就会被置为0。
opcode 中最低的 3 位是 instruction class (cls),将 opcodes 分了组,具体为下面几种
LD/LDX/ST/STX opcode 具有如下结构
msb lsb
+---+--+---+
|mde|sz|cls|
+---+--+---+
其中两位的 sz 域指定了内存位置的大小,3 位的 mde 域是内存获取模式,uBPF 只支持通用的 "MEM" 获取方式。
ALU/ALU64/JMP opcode 具有如下结构
msb lsb
+----+-+---+
|op |s|cls|
+----+-+---+
如果 s 位是 0,那么 source operand 就会是指令中立即数 imm 对应的域。如果 s 是 1,那么 source operand 就会是指令中 src 域。4 位的 op 域则指定了将要执行哪个 ALU 或 branch 操作。
ALU 指令
64-bit
| Opcode | Mnemonic | Pseudocode |
|---|---|---|
| 0x07 | add dst, imm | dst += imm |
| 0x0f | add dst, src | dst += src |
| 0x17 | sub dst, imm | dst -= imm |
| 0x1f | sub dst, src | dst -= src |
| 0x27 | mul dst, imm | dst *= imm |
| 0x2f | mul dst, src | dst *= src |
| 0x37 | div dst, imm | dst /= imm |
| 0x3f | div dst, src | dst /= src |
| 0x47 | or dst, imm | dst |= imm |
| 0x4f | or dst, src | dst |= src |
| 0x57 | and dst, imm | dst &= imm |
| 0x5f | and dst, src | dst &= src |
| 0x67 | lsh dst, imm | dst <<= imm |
| 0x6f | lsh dst, src | dst <<= src |
| 0x77 | rsh dst, imm | dst >>= imm (logical) |
| 0x7f | rsh dst, src | dst >>= src (logical) |
| 0x87 | neg dst | dst = -dst |
| 0x97 | mod dst, imm | dst %= imm |
| 0x9f | mod dst, src | dst %= src |
| 0xa7 | xor dst, imm | dst ^= imm |
| 0xaf | xor dst, src | dst ^= src |
| 0xb7 | mov dst, imm | dst = imm |
| 0xbf | mov dst, src | dst = src |
| 0xc7 | arsh dst, imm | dst >>= imm (arithmetic) |
| 0xcf | arsh dst, src | dst >>= src (arithmetic) |
32-bit
这些指令只使用低的 32 位,并且会将目标寄存器的高 32 位置零。
| Opcode | Mnemonic | Pseudocode |
|---|---|---|
| 0x04 | add32 dst, imm | dst += imm |
| 0x0c | add32 dst, src | dst += src |
| 0x14 | sub32 dst, imm | dst -= imm |
| 0x1c | sub32 dst, src | dst -= src |
| 0x24 | mul32 dst, imm | dst *= imm |
| 0x2c | mul32 dst, src | dst *= src |
| 0x34 | div32 dst, imm | dst /= imm |
| 0x3c | div32 dst, src | dst /= src |
| 0x44 | or32 dst, imm | dst |= imm |
| 0x4c | or32 dst, src | dst |= src |
| 0x54 | and32 dst, imm | dst &= imm |
| 0x5c | and32 dst, src | dst &= src |
| 0x64 | lsh32 dst, imm | dst <<= imm |
| 0x6c | lsh32 dst, src | dst <<= src |
| 0x74 | rsh32 dst, imm | dst >>= imm (logical) |
| 0x7c | rsh32 dst, src | dst >>= src (logical) |
| 0x84 | neg32 dst | dst = -dst |
| 0x94 | mod32 dst, imm | dst %= imm |
| 0x9c | mod32 dst, src | dst %= src |
| 0xa4 | xor32 dst, imm | dst ^= imm |
| 0xac | xor32 dst, src | dst ^= src |
| 0xb4 | mov32 dst, imm | dst = imm |
| 0xbc | mov32 dst, src | dst = src |
| 0xc4 | arsh32 dst, imm | dst >>= imm (arithmetic) |
| 0xcc | arsh32 dst, src | dst >>= src (arithmetic) |
Byteswap 指令
| Opcode | Mnemonic | Pseudocode |
|---|---|---|
| 0xd4 (imm == 16) | le16 dst | dst = htole16(dst) |
| 0xd4 (imm == 32) | le32 dst | dst = htole32(dst) |
| 0xd4 (imm == 64) | le64 dst | dst = htole64(dst) |
| 0xdc (imm == 16) | be16 dst | dst = htobe16(dst) |
| 0xdc (imm == 32) | be32 dst | dst = htobe32(dst) |
| 0xdc (imm == 64) | be64 dst | dst = htobe64(dst) |
Memory 指令
| Opcode | Mnemonic | Pseudocode |
|---|---|---|
| 0x18 | lddw dst, imm | dst = imm |
| 0x20 | ldabsw src, dst, imm | See kernel documentation |
| 0x28 | ldabsh src, dst, imm | ... |
| 0x30 | ldabsb src, dst, imm | ... |
| 0x38 | ldabsdw src, dst, imm | ... |
| 0x40 | ldindw src, dst, imm | ... |
| 0x48 | ldindh src, dst, imm | ... |
| 0x50 | ldindb src, dst, imm | ... |
| 0x58 | ldinddw src, dst, imm | ... |
| 0x61 | ldxw dst, [src+off] | dst = *(uint32_t *) (src + off) |
| 0x69 | ldxh dst, [src+off] | dst = *(uint16_t *) (src + off) |
| 0x71 | ldxb dst, [src+off] | dst = *(uint8_t *) (src + off) |
| 0x79 | ldxdw dst, [src+off] | dst = *(uint64_t *) (src + off) |
| 0x62 | stw [dst+off], imm | *(uint32_t *) (dst + off) = imm |
| 0x6a | sth [dst+off], imm | *(uint16_t *) (dst + off) = imm |
| 0x72 | stb [dst+off], imm | *(uint8_t *) (dst + off) = imm |
| 0x7a | stdw [dst+off], imm | *(uint64_t *) (dst + off) = imm |
| 0x63 | stxw [dst+off], src | *(uint32_t *) (dst + off) = src |
| 0x6b | stxh [dst+off], src | *(uint16_t *) (dst + off) = src |
| 0x73 | stxb [dst+off], src | *(uint8_t *) (dst + off) = src |
| 0x7b | stxdw [dst+off], src | *(uint64_t *) (dst + off) = src |
Branch 指令
| Opcode | Mnemonic | Pseudocode |
|---|---|---|
| 0x05 | ja +off | PC += off |
| 0x15 | jeq dst, imm, +off | PC += off if dst == imm |
| 0x1d | jeq dst, src, +off | PC += off if dst == src |
| 0x25 | jgt dst, imm, +off | PC += off if dst > imm |
| 0x2d | jgt dst, src, +off | PC += off if dst > src |
| 0x35 | jge dst, imm, +off | PC += off if dst >= imm |
| 0x3d | jge dst, src, +off | PC += off if dst >= src |
| 0xa5 | jlt dst, imm, +off | PC += off if dst < imm |
| 0xad | jlt dst, src, +off | PC += off if dst < src |
| 0xb5 | jle dst, imm, +off | PC += off if dst <= imm |
| 0xbd | jle dst, src, +off | PC += off if dst <= src |
| 0x45 | jset dst, imm, +off | PC += off if dst & imm |
| 0x4d | jset dst, src, +off | PC += off if dst & src |
| 0x55 | jne dst, imm, +off | PC += off if dst != imm |
| 0x5d | jne dst, src, +off | PC += off if dst != src |
| 0x65 | jsgt dst, imm, +off | PC += off if dst > imm (signed) |
| 0x6d | jsgt dst, src, +off | PC += off if dst > src (signed) |
| 0x75 | jsge dst, imm, +off | PC += off if dst >= imm (signed) |
| 0x7d | jsge dst, src, +off | PC += off if dst >= src (signed) |
| 0xc5 | jslt dst, imm, +off | PC += off if dst < imm (signed) |
| 0xcd | jslt dst, src, +off | PC += off if dst < src (signed) |
| 0xd5 | jsle dst, imm, +off | PC += off if dst <= imm (signed) |
| 0xdd | jsle dst, src, +off | PC += off if dst <= src (signed) |
| 0x85 | call imm | Function call |
| 0x95 | exit | return r0 |
更加详细的协议参考内核 bpf 相关文档
常见的 bpf_prog_type
| bpf_prog_type | BPF prog 入口参数(R1) | 程序类型 |
|---|---|---|
| BPF_PROG_TYPE_SOCKET_FILTER | struct __sk_buff | 用于过滤进出口网络报文,功能上和 cBPF 类似。 |
| BPF_PROG_TYPE_KPROBE | struct pt_regs | 用于 kprobe 功能的 BPF 代码。 |
| BPF_PROG_TYPE_TRACEPOINT | 这类 BPF 的参数比较特殊,根据 tracepoint 位置的不同而不同。 | 用于在各个 tracepoint 节点运行。 |
| BPF_PROG_TYPE_XDP | struct xdp_md | 用于控制 XDP(eXtreme Data Path)的 BPF 代码。 |
| BPF_PROG_TYPE_PERF_EVENT | struct bpf_perf_event_data | 用于定义 perf event 发生时回调的 BPF 代码。 |
| BPF_PROG_TYPE_CGROUP_SKB | struct __sk_buff | 用于在 network cgroup 中运行的 BPF 代码。功能上和 Socket_Filter 近似。具体用法可以参考范例 test_cgrp2_attach。 |
| BPF_PROG_TYPE_CGROUP_SOCK | struct bpf_sock | 另一个用于在 network cgroup 中运行的 BPF 代码,范例 test_cgrp2_sock2 中就展示了一个利用 BPF 来控制 host 和 netns 间通信的例子。 |
与网络相关的有XDP、socket、tc等。
事实上 BPF 程序类型就是由 BPF side 的代码的函数参数确定的,比如写了一个函数,参数是 struct __sk_buff 类型的,它就是一个 BPF_PROG_TYPE_SOCKET_FILTER 类型的 BPF 程序。
其他的 BPF 相关概念
Helper Function
BPF 系统调用的原型如下:
c
#include <linux/bpf.h>
int bpf(int cmd, union bpf_attr *attr, unsigned int size);
bpf系统调用要执行的操作由 cmd 参数确定。每个操作都有一个附带的参数,通过 attr 提供,size 参数是 attr 的大小。
cmd 参数可以是一系列 helper 的宏定义,如 BPF_MAP_CREATE、 BPF_MAP_LOOKUP_ELEM、BPF_MAP_UPDATE_ELEM、BPF_MAP_DELETE_ELEM、BPF_MAP_GET_NEXT_KEY、BPF_PROG_LOAD;分别是对应 map 创建、map 中元素查找、map 中更新元素、map 中删除元素、获取相邻的 key、加载 bpf 程序。bpf_attr 则相当复杂,不展开说了,实际上也很少直接使用该系统调用,都是使用 BPF helper 函数的。
Helper functions 是一些与内核交互的常用 API, 可以从内核获取或写入数据。不同的 BPF 程序类型 bpf_prog_type 可用的 helper function 不同,例如与 socket 有关的 BPF 函数就只允许使用一小部分的 helpers,而与 tc (traffic control 的缩写,更加靠近传输层,而且此时包都还没解析)相关的 BPF 函数可以调用更多的 helpers。
内核将 helper 函数抽象到了宏 BPF_CALL_0() 到 BPF_CALL_5(),让定义过程更加简单,更加可读。下面这个例子就节选自一个用来更新映射元素的 helper function,它调用了映射上实现的相关的回调函数
c
// 注意这是一个宏
BPF_CALL_4(bpf_map_update_elem, struct bpf_map *, map, void *, key,
void *, value, u64, flags)
{
WARN_ON_ONCE(!rcu_read_lock_held());
return map->ops->map_update_elem(map, key, value, flags);
}
const struct bpf_func_proto bpf_map_update_elem_proto = {
.func = bpf_map_update_elem,
.gpl_only = false,
.ret_type = RET_INTEGER,
.arg1_type = ARG_CONST_MAP_PTR,
.arg2_type = ARG_PTR_TO_MAP_KEY,
.arg3_type = ARG_PTR_TO_MAP_VALUE,
.arg4_type = ARG_ANYTHING,
};
这种提前定义宏的好处是:在 cBPF 中,当添加新的 helper时,JIT 需要对这种扩展做支持;但是在 eBPF 中,底层的 BPF 寄存器的分配已经提前做好了,JIT 此时只需要触发一个调用指令。因此 eBPF 的 helper functions 更容易拓展。
helper functions 数量众多,可以参考附录中的eBPF-Helpers。
Verifier
上面 helper function 代码中的 bpf_func_proto 是用来传递 verifier 的必要数据的,用来验证 helper 提供的参数类型和当下 BPF 寄存器中的内容符合。参数类型可以是任意的值,也可以是针对一个 buffer 的 <指针,大小> 的数据对,告诉 helper 它应该从哪里读取数据或写入数据, verifier 会验证 buffer 之前是否有被初始化过。
In-kernel Verifier还会验证:
- 对注入代码进行一次 DAG(Directed Acyclic Graph,有向无环图)检测,以保证其中没有循环存在
- eBPF 的代码长度上限为 4096 条 BPF 指令(在内核 5.1 版本以上,这个上限提升到了 100 万)。
- 存在可能会跳出 eBPF 代码范围的 JMP
- 分支(branch)不允许超过 1024 个;经检测的指令数也必须在 96K 以内
- 支持运行尾调用(tail calls),即在 eBPF 程序末尾调用另一个 eBPF 程序,但是也是有限制的,最多可以嵌套 33 次 尾调用
- BPF helper 函数中最多允许5个函数参数
verifier执行的第一个检查是对VM将要加载的代码的静态分析。第一次检查的目的是确保程序有一个预期的结束。为此,verifier 使用代码创建一个直接非循环图(DAG)。verifier 分析的每条指令都成为图中的一个节点,每个节点都链接到下一条指令。在 verifier 生成这个图之后,它将执行深度优先搜索(DFS),以确保程序完成并且代码不包含危险路径。这意味着它将遍历图的每个分支,一直遍历到分支的底部,以确保没有递归循环。
verifier 执行的第二个检查是BPF程序的一个空运行。这意味着verifier将尝试分析程序将要执行的每条指令,以确保它不会执行任何无效的指令。此执行还检查是否正确访问和取消引用了所有内存指针。最后,空运行将程序中的控制流通知 verifier,以确保无论程序采用哪种控制路径,它都会到达 BPF_EXIT 指令。为此,verifier 跟踪堆栈中所有已访问的分支路径,在选择新路径之前对其进行评估,以确保不会多次访问特定路径。在这两个检查通过之后,verifier 认为程序可以安全地执行。
bpf 系统调用允许您 debug verifier 的检查,如果您对分析程序如何被分析感兴趣的话。使用此系统调用加载程序时,可以设置几个属性,使验证器打印其操作日志。
Maps
BPF 映射是内核中的键值型数据结构,他们能够从 BPF 程序中获取,来在不同的 BPF 调用之间传递状态信息。他们也能通过用户空间的文件描述符来获取,也能在 BPF 程序或用户空间的应用之间共享。注意共享 BPF 映射的 BPF 程序不一定是相同的程序类型,例如,一个 tracing 程序也可能可以和网络程序共享映射,当下一个单独的 BPF 程序最多可以同时获取到 64 个不同的映射。
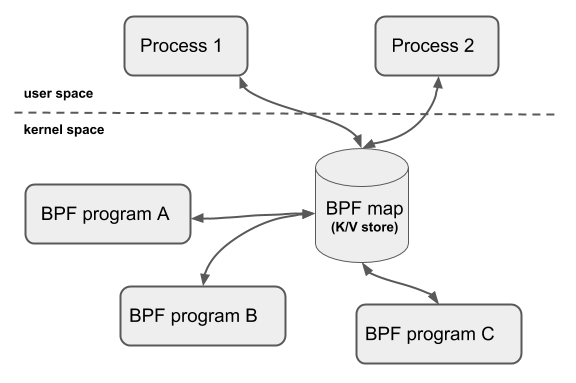
映射的实现是在内核中,有通用的,也有仅能在少数 helper functions 中使用的。通用的映射有BPF_MAP_TYPE_HASH, BPF_MAP_TYPE_ARRAY, BPF_MAP_TYPE_PERCPU_HASH, BPF_MAP_TYPE_PERCPU_ARRAY, BPF_MAP_TYPE_LRU_HASH, BPF_MAP_TYPE_LRU_PERCPU_HASH and BPF_MAP_TYPE_LPM_TRIE。他们都是用的是相同的 BPF helper functions 来实现增删查改,同时针对不同的语义和应用特征实现了不同的后端操作。
现有的不通用的映射有 BPF_MAP_TYPE_PROG_ARRAY, BPF_MAP_TYPE_PERF_EVENT_ARRAY, BPF_MAP_TYPE_CGROUP_ARRAY, BPF_MAP_TYPE_STACK_TRACE, BPF_MAP_TYPE_ARRAY_OF_MAPS, BPF_MAP_TYPE_HASH_OF_MAPS。例如,BPF_MAP_TYPE_PROG_ARRAY 是一个包含有其他 BPF 程序的数组, BPF_MAP_TYPE_ARRAY_OF_MAPS 和 BPF_MAP_TYPE_HASH_OF_MAPS 都持有着指向其他映射的指针,为了在运行时能原子地更换 BPF 映射。通过这种实现满足了这个特殊的需求。因为状态是需要在不同的 BPF 程序调用中共享的,所以不能单独通过一个 BPF helper function实现,而是要用这种方法。
补充 MAP 类型细节:
- BPF_MAP_TYPE_HASH:第一个添加到BPF的通用 map。它们的实现和用法类似于您可能熟悉的其他哈希表。
- BPF_MAP_TYPE_ARRAY:添加到内核的第二种 BPF 映射。它的所有元素都在内存中预先分配并设置为零值。键是数组中的索引,它们的大小必须正好是4个字节。使用 Array maps 的一个缺点是不能删除map中的元素。如果尝试在 array maps 上使用map_delete_elem,则调用将失败,结果将导致错误 EINVAL。
- BPF_MAP_TYPE_PROG_ARRAY:您可以使用这种类型的 map,来存储BPF程序的文件描述。与 bpf_tail_call 调用结合,此 map 允许您在程序之间跳转,绕过单个 bpf 程序的最大指令限制,并降低实现复杂性。
- BPF_MAP_TYPE_PERF_EVENT_ARRAY:这些类型的 map 将 perf_events 数据存储在缓冲环中,缓冲环在BPF程序和用户空间程序之间实时通信。它们被设计用来将内核的跟踪工具发出的事件转发给用户空间程序进行进一步处理。
- BPF_MAP_TYPE_PERCPU_HASH:Per-CPU Hash Maps 是 BPF_MAP_TYPE_HASH 的改进版本。当您分配其中一个 map 时,每个CPU都会看到自己独立的map版本,这使得它更高效地进行高性能的查找和聚合。如果您的BPF程序收集度量并将它们聚合到 hash-table maps中,那么这种map非常有用。
- BPF_MAP_TYPE_PERCPU_ARRAY:Per-CPU Array Maps 是 BPF_MAP_TYPE_ARRAY 的改进版本。当您分配这些 map 中的一个时,每个CPU都会看到自己的独立版本的 map,这使得它更高效地进行高性能的查找和聚合。
- BPF_MAP_TYPE_STACK_TRACE:这种类型的 map 存储运行进程的堆栈跟踪。除了这个 map 之外,内核开发人员已经添加了帮助函数bpf_get_stackid来帮助您用堆栈跟踪填充这个映射。
- BPF_MAP_TYPE_CGROUP_ARRAY:这种类型的 map 存储指向 cgroup 的文件描述符标识符。 BPF_MAP_TYPE_LRU_HASH and BPF_MAP_TYPE_LRU_PERCPU_HASH:如果 map 满了,删除不常使用的 map,为新元素提供空间。percpu 则是针对每个 cpu。
- BPF_MAP_TYPE_LPM_TRIE:一个匹配最长前缀的字典树数据结构,适用于将 IP 地址匹配到一个范围。这些 map 要求其 key 大小为 8 的倍数,范围为 8 到 2048。如果您不想实现自己的 key,那么内核提供了一个可以用于这些 key 的结构,称为 bpf_lpm_trie_key。
- BPF_MAP_TYPE_ARRAY_OF_MAPS and BPF_MAP_TYPE_HASH_OF_MAPS:存储对其他映射的引用的两种类型的映射。它们只支持一个级别的间接寻址。
- BPF_MAP_TYPE_DEVMAP:存储对网络设备的引用。可以构建指向特定网络设备的端口的虚拟映射,然后使用 bpf_redirect_map 重定向数据包。
- BPF_MAP_TYPE_CPUMAP:可以将数据包转发到不同的 cpu
- BPF_MAP_TYPE_XSKMAP:一种存储对打开的套接字的引用的映射类型。用于套接字转发。
- BPF_MAP_TYPE_SOCKMAP和BPF_MAP_TYPE_SOCKHASH 是两个专门的 map。它们存储对内核中打开的套接字的引用。与前面的映射一样,这种类型的映射与 bpf_redirect_map 一起使用,将套接字缓冲区从当前 XDP 程序转发到不同的套接字。
- BPF_MAP_TYPE_CGROUP_STORAGE 和 BPF_MAP_TYPE_PERCPU_CGROUP_STORAGE:略
- BPF_MAP_TYPE_REUSEPORT_SOCKARRAY:略
- BPF_MAP_TYPE_QUEUE:队列映射使用先进先出(FIFO)存储来保存映射中的元素。它们是用 BPF_MAP_TYPE_QUEUE 类型定义的。FIFO 意味着,当您从映射中获取一个元素时,结果将是映射中存在时间最长的元素。 BPF_MAP_TYPE_STACK:栈映射使用后进先出(LIFO)存储来保存映射中的元素。它们是用类型 BPF_MAP_TYPE_STACK 定义的。后进先出意味着,当您从映射中获取元素时,结果将是最近添加到映射中的元素。
Object Pinning
BPF 映射和程序是一种内核资源,只能通过文件描述符相关的 API 来获取它们。更底层的是匿名的索引节点(内核中的 inodes)。这种做法有许多优势和劣势:
用户空间的应用程序能够使用大多数文件描述符相关的 API,文件描述符在 Unix 内部的 socket 通讯中是透明的,但是与此同时,文件描述符又只能在程序的生命周期内使用,这使得映射的共享难以实现。
因此它带来了一系列棘手的复杂情况,例如在 iproute2 中,tc 和 XDP 在内核中启动并加载后最终会消亡掉。这样不可能从用户空间获取映射了。但是从用户空间获取映射是很有用的,例如,当映射在 data path 的入口位置和出口位置之间共享时。同时,第三方应用也可能想要在 BPF 程序运行时去监测或更新映射内容。
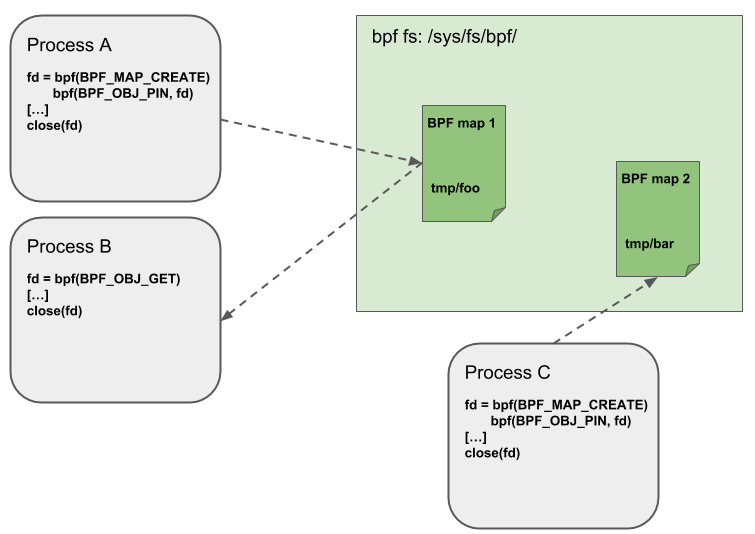
为了突破这种限制,实现了一小部分内核空间的 BPF 文件系统。在这里, BPF 映射和程序能够被钉在上面,也叫作 object pinning。BPF 系统调用也进行了一定拓展,支持了两个新的命令,可以支持钉上(BPF_OBJ_PIN)或获取(BPF_OBJ_GET)这两种行为。
BPF 的文件系统不是单例,它支持挂载多个实例、硬或软链接。
Tail Calls
尾调用能够允许一个 BPF 程序去调用另一个,不需要返回旧的程序中。这种调用方式开销很小,和函数调用不同,它在是用 long jump 命令实现的,可以直接复用相同的栈帧(即常见的尾递归优化)。
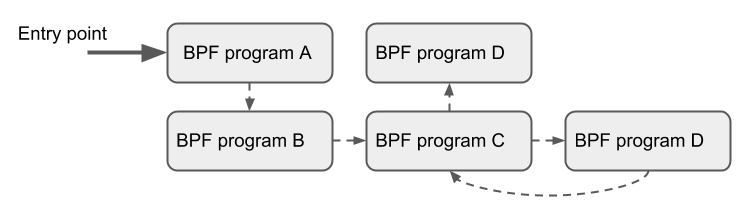
这样的程序能够独立进行验证。但是只有相同类型的 BPF 程序(即 bpf_prog_type 相同)才能进行尾调用;同时在 JIT 方面也要匹配, 即尾调用中 JIT 代码只能接在 JIT 代码后,直接解释的代码只能接在直接解释的代码后,不能在另一类代码后进行尾调用。
尾调用相关操作有两部分:第一部分是建立一个叫做程序数组的特殊的映射(BPF_MAP_TYPE_PROG_ARRAY),能在用户空间进行键值数据的修改,值就是尾调用 BPF 程序的文件描述符。第二部分是bpf_tail_call()帮助函数,它需要传入上下文(context)、程序数组的引用、和想查询的键。内核会把这个帮助函数内联到特定的 BPF 指令中。这个程序数组在用户空间是 write-only 的。
内核根据提供的文件描述符查找相关的 BPF 程序,原子地替换掉给定的映射槽处的程序指针。当在映射中按照所给键值找不到指针时,内核会跳过它然后接着执行bpf_tail_call() 之后的函数。尾调用很有用,例如在解析网络数据包时,就可以使用尾调用逐层解析。
BPF to BPF Calls
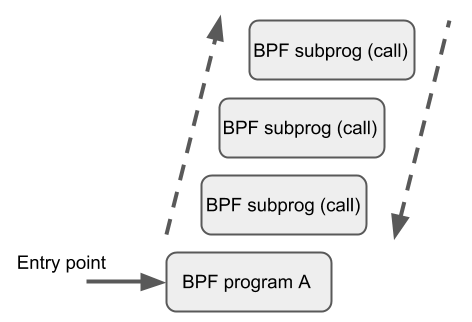
除了 BPF helper 函数和 BPF 尾调用,一个新添加的特性是 BPF 程序调用 BPF 程序。在这个特性被引入内核之前,一般 BPF C 程序需要定义一些可重用代码,单独存在一个头文件中,他们都是 always_inline 的。使用 LLVM 进行编译的时候,这些可重用代码会被内联到需要的地方,导致生成的代码体积很大。具体形式如下:
C
#include <linux/bpf.h>
#ifndef __section
# define __section(NAME) \
__attribute__((section(NAME), used))
#endif
#ifndef __inline
# define __inline \
inline __attribute__((always_inline))
#endif
static __inline int foo(void)
{
return XDP_DROP;
}
__section("prog")
int xdp_drop(struct xdp_md *ctx)
{
return foo();
}
char __license[] __section("license") = "GPL";
这么干的原因就是在 BPF 验证器、加载器、解释器、JIT 中都缺少对函数的支持。从Linux 4.16, LLVM 6.0 开始,就支持这个特性了。BPF 程序不必再到处使用 always_inline 标签了,前面的代码可以被更自然地表达为
C
#include <linux/bpf.h>
#ifndef __section
# define __section(NAME) \
__attribute__((section(NAME), used))
#endif
static int foo(void)
{
return XDP_DROP;
}
__section("prog")
int xdp_drop(struct xdp_md *ctx)
{
return foo();
}
char __license[] __section("license") = "GPL";
主流的 BPF JIT 编译器例如在 x86_64 和 arm64 上的会支持 BPF 到 BPF 的调用,其他则会添加类似的特性。这个特性对性能优化意义重大,因为它显著减少了生成的 BPF 代码的大小。因此从指令缓存的角度,这样生成的机器码对 CPU 更加友好。
BPF 函数之间的调用方法和 BPF helper 函数的调用方法一致,意味着从 r1 到 r5 这五个寄存器都是用来向被调用的函数传递参数的(回忆:BPF helper 函数中最多允许5个函数参数),函数运行结果返回到寄存器r0。寄存器 r1 到 r5 都是暂存寄存器,而寄存器r6 到 r9 则可以在不同调用之间保存数据。最大允许的调用深度是8。一个调用者可以传递指针(如调用者的栈帧)给被调用方,反过来不行。
BPF JIT 编译器为每个函数编译出单独的映像,JIT 最终会修正映像中的函数调用地址将他们串联起来。事实证明,这样对 JIT 进行的改动最小,因为使用这种方法 JIT 可以将BPF到BPF的调用视为常规的 BPF helper 函数调用。
知道 Linux 5.9,BPF 尾调用和 BPF 子程序都相互排斥,使用了尾调用的 BPF 程序不能使用 BPF 子程序来减小生成的程序映像大小、加速程序加载。之后的 Linux 5.10 最终允许了用户能够同时利用二者的优点,使得 BPF 子程序和尾递归可以同时使用了。
这个改进是有代价的,将这两个特性混合在一起可能会造成内核堆栈溢出。为了一窥其中奥秘,可以看下面这张图片,它就解释了二者是如何混合的:
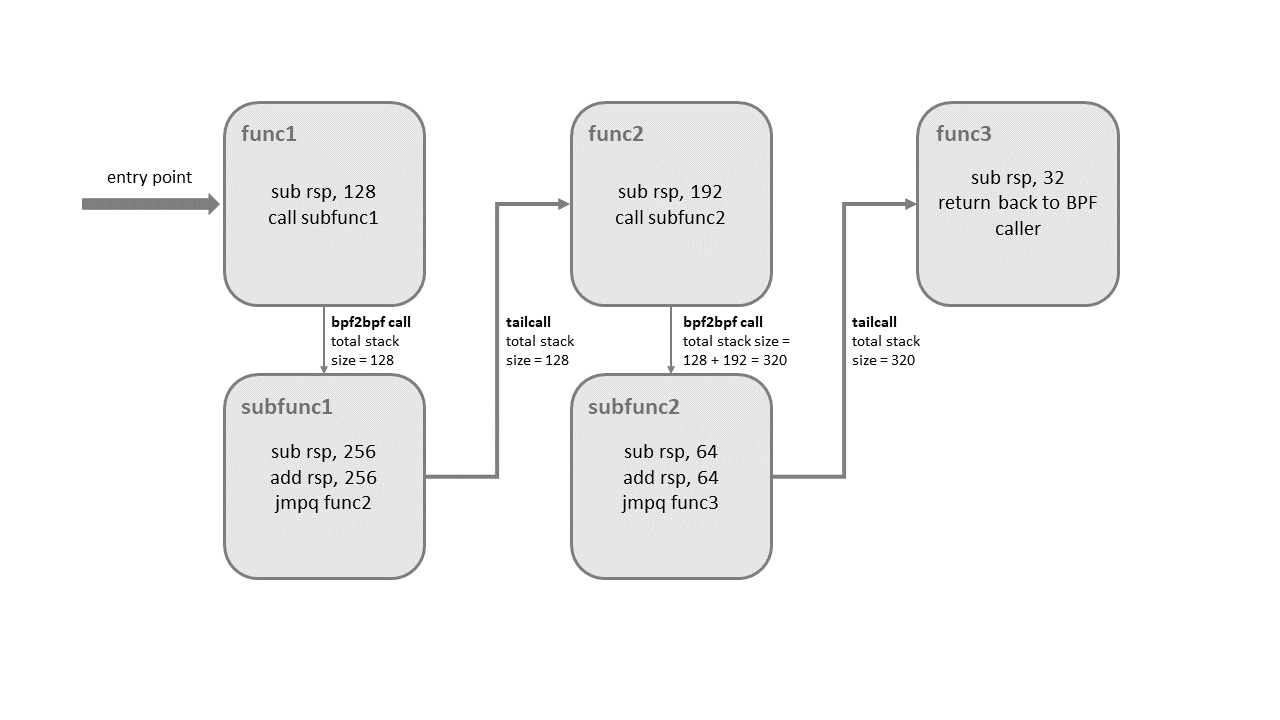
尾调用不改变栈顶指针位置,在真正跳转到目标程序地址之前,会把当前栈帧释放掉。正如我们在上面例子里看到的,如果一个尾调用在子函数 subfunc1 中发生了,调用了func2,那么 func1 的栈帧将会在栈中存在下去。一旦最终的 func3 函数终结了,所有前面的栈帧都会被展开控制权会回到 BPF 函数调用方。
内核引入了别的逻辑来检测这两个特性的结合。在上图的整个链式调用中,对每个子程序的栈的大小限制为 256 字节,注意如果验证器检测到了 BPF2BPF 调用,那么主函数也会被视为是一个子函数(即整个链上大家都有这个栈大小的限制)。凭借这个限制,BPF 程序调用链最多能够消耗 8KB 大小的栈空间。这个上限的计算方式是每个栈帧 256 字节,乘上尾调用上限 33。没有这个限制,BPF 程序能够使用512 字节的栈空间,则最大可能会占用 16KB 的栈,最终可能会在某些架构的机器上就堆栈溢出了。
另一个值得一提的点是这种特性的结合限制只在 x86-64 架构上得到了支持。
JIT
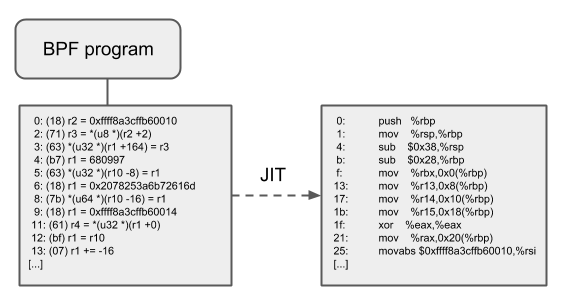
64 位的 x86_64、 arm64、 ppc64、 s390x、 mips64、 sparc64 和 32 位的 arm、x86_32 架构都在内核中写好了eBPF JIT 编译器,他们都有着相同的特性,可以使用下面的方式激活
# echo 1 > /proc/sys/net/core/bpf_jit_enable
32 位的 mips、 ppc 和sparc 的架构现在有一个 cBPF JIT 编译器。上面提到的架构也依然有 cBPF JIT,其他架构没有 JIT,只能通过内核中的解释器来跑。
在内核源码树中,能够轻易地被找到 eBPF JIT 的相关支持,只需要 git grep 一下 HAVE_EBPF_JIT:
# git grep HAVE_EBPF_JIT arch/
arch/arm/Kconfig: select HAVE_EBPF_JIT if !CPU_ENDIAN_BE32
arch/arm64/Kconfig: select HAVE_EBPF_JIT
arch/powerpc/Kconfig: select HAVE_EBPF_JIT if PPC64
arch/mips/Kconfig: select HAVE_EBPF_JIT if (64BIT && !CPU_MICROMIPS)
arch/s390/Kconfig: select HAVE_EBPF_JIT if PACK_STACK && HAVE_MARCH_Z196_FEATURES
arch/sparc/Kconfig: select HAVE_EBPF_JIT if SPARC64
arch/x86/Kconfig: select HAVE_EBPF_JIT if X86_64
JIT 编译器能够显著加速 BPF 程序的执行,因为相比于解释器他们减少了单指令的开销。通常指令都能够一一映射到底层架构上的原始指令上。这也减少了最终的可执行映像大小,因而对 CPU 指令缓存来说更为友好。特别是在复杂的 CISC 指令集下,例如 x86,JITs 都会被优化以生成最精悍的指令,来减少程序翻译后的大小。
Hardening
BPF 将整个 BPF 解释器映像(struct bpf_prog)和 JIT 编译出的映像(struct bpf_binary_header)在程序生命周期内在内核中是只读的,以防止潜在的代码损坏。例如出于内核的 bug,代码可能会损坏,进而导致内核宕机。
支持将将映像设置为只读的架构能够通过下面的方式查看,同样是使用git grep:
$ git grep ARCH_HAS_SET_MEMORY | grep select
arch/arm/Kconfig: select ARCH_HAS_SET_MEMORY
arch/arm64/Kconfig: select ARCH_HAS_SET_MEMORY
arch/s390/Kconfig: select ARCH_HAS_SET_MEMORY
arch/x86/Kconfig: select ARCH_HAS_SET_MEMORY
选项 CONFIG_ARCH_HAS_SET_MEMORY 不是可配置的,它总是内置的。其他架构在未来也可能会支持这一特性。
对于x86_64 JIT 编译器,假设它在写操作会设置 CONFIG_RETPOLINE 项(通常现代操作系统都会这么干),那么JIT 地从尾调用中编译 indirect jump 是通过一个 retpoline 来实现的(retpoline 是用来缓解内核或跨进程内存泄露的,又称 Spectre 攻击,参考lkml 邮件)。
当 /proc/sys/net/core/bpf_jit_harden 设置为 1 的时候,另一个针对非管理员用户的 JIT 编译的 hardening 操作生效了。这会稍微牺牲性能,以减少来自未信任的用户的潜在的攻击。即使牺牲了性能,表现仍然是比直接完全地使用解释器要好。
当下,激活 hardening 后,使用 JIT 编译 BPF 程序,会屏蔽 BPF 程序中所有用户提供的 32 位和 64 位常量,以应对 JIT spraying attacks。JIT spraying attacks 会注入原生指令的 opcode 作为立即数。这会带来很大的问题,因为这些立即数是存储在可执行的内核内存区域中。如果因为某些内核 bug,程序计数器跳转到了被注入的指令处,可能会执行这些被注入的程序。
JIT 常量屏蔽可以通过随机化真正的指令避免这种情况,意味着最后的指令运算通过重写指令,将一个基于立即数的指令码,转换到了基于寄存器的指令码。重写指令的方法共两步:加载一个被随机屏蔽的立即数 rnd ^ imm 到寄存器中,使用rnd 与寄存器中的值做异或,在寄存器中得到初始的 imm 立即数,能够用来做真正的指令运算。下面的例子展示了一个 load 指令操作,其他常见的指令也都是这么屏蔽的。在 hardening 禁用的情况下使用 JIT 编译一个程序的例子:
# echo 0 > /proc/sys/net/core/bpf_jit_harden
ffffffffa034f5e9 + <x>:
[...]
39: mov $0xa8909090,%eax
3e: mov $0xa8909090,%eax
43: mov $0xa8ff3148,%eax
48: mov $0xa89081b4,%eax
4d: mov $0xa8900bb0,%eax
52: mov $0xa810e0c1,%eax
57: mov $0xa8908eb4,%eax
5c: mov $0xa89020b0,%eax
[...]
相同的程序,当开启了 hardening 时,以非管理员用户加载 BPF 程序时,常量会被屏蔽:
# echo 1 > /proc/sys/net/core/bpf_jit_harden
ffffffffa034f1e5 + <x>:
[...]
39: mov $0xe1192563,%r10d
3f: xor $0x4989b5f3,%r10d
46: mov %r10d,%eax
49: mov $0xb8296d93,%r10d
4f: xor $0x10b9fd03,%r10d
56: mov %r10d,%eax
59: mov $0x8c381146,%r10d
5f: xor $0x24c7200e,%r10d
66: mov %r10d,%eax
69: mov $0xeb2a830e,%r10d
6f: xor $0x43ba02ba,%r10d
76: mov %r10d,%eax
79: mov $0xd9730af,%r10d
7f: xor $0xa5073b1f,%r10d
86: mov %r10d,%eax
89: mov $0x9a45662b,%r10d
8f: xor $0x325586ea,%r10d
96: mov %r10d,%eax
[...]
两个程序在语义上是等价的,除了原始代码中的立即数在第二个程序的反汇编中都无法再看得到了。
与此同时,hardening 也禁用了对管理员用户的 JIT kallsyms exposure,JIT 映像的地址不再暴露给 /proc/kallsyms 。
另外, Linux 内核也提供了选项 CONFIG_BPF_JIT_ALWAYS_ON,从内核中移除整个 BPF 解释器并永久地激活 JIT 编译器。在使用基于 VM 的设置的 Spectre v2 环境下,当客户机不打算使用宿主机内核的 BPF 解释器来装载 Spectre 攻击的时候,这也被发展成了内核移植的一部分。对于基于容器的环境,选项 CONFIG_BPF_JIT_ALWAYS_ON 是可选的,但是在 JIT 被激活的情况下,解释器可能也被编译出来了以减轻内核的复杂程度。因此,在主流的结构中,例如x86_64 和 arm64 中,对广泛使用的 JIT,通常也建议开启这个选项。
最后,内核提供了一个选项来禁止非管理员用户使用 bpf(2) 系统调用,这是通过 /proc/sys/kernel/unprivileged_bpf_disabled sysctl knob 实现的。这是一个一次性的开关,意味着一旦设置为 1,没有其他选项能够把它变为 0,直到内核重启。当只设置 CAP_SYS_ADMIN 时,离开初始空间的管理员进程从这之后就能够使用 bpf(2) 系统调用。
# echo 1 > /proc/sys/kernel/unprivileged_bpf_disabled
Offloads
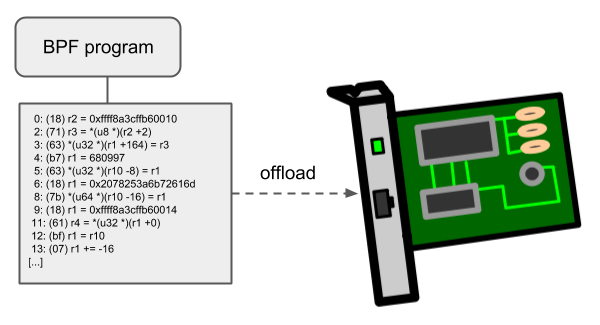
BPF 写的网络相关的程序,特别是 tc 和 XDP 相关程序,都有 offload-interface,可以脱离内核在网卡中执行 BPF 代码(直接在网卡中处理因而因而更加高效甚至不用内核参与)。
当下,Netronome 的驱动 nfp 已经支持了通过 JIT 编译器将 BPF 程序编译到网卡上特定指令集。也支持了 BPF maps,因此在网卡上 BPF 程序也能实现映射的查询、更新和删除。
BPF 虚拟机的具体实现
Linux 内核中当然是有 BPF 的 虚拟机实现的,但是内核代码浩如烟海,而且是内核态的实现。
用户态的虚拟机实现有:
iovisor 组织用 C 重写了一个 ubpf。类似的有仿照 ubpf 写的 rust 版本 rbpf。
但是ubpf 只支持 x86-64,rbpf 仿照了前者的代码,作者表示没有时间去做其他架构的支持。
同时他们都是在运行期间做的地址验证,实际上没有提前做验证。如 ubpf 对 memory 相关 load/ store 指令的地址验证就是只能在运行期进行,同时它没有对栈的地址做验证 (所以 ubpf 和 rbpf 为啥要做两次循环……一次验证一次运行……)。
STM32MP157 开发板上,小核是 Cortex-M4,Cortex-M4 是使用的是 ARMv7-M 架构,可以参考ARMV7-M Documentation – Arm Developer。
仿照 x86-64 的实现去为 ARM v7-M 实现一套。首先看字节序,x86-64 是小端的,ARM v7-M 默认也是小端,这点可以放心了。
下面的章节分析一下 x86-64 和 ARMv7-M 寄存器的映射,然后就可以着手看怎么改了。
最后移植到开发板上试一下~效果如下图。
后续的工作的话:
考虑把腾讯的那个物联网实时操作系统的移植和这里 BPF 虚拟机的移植整合一下,实现多任务处理~
有空给ubpf 和 rbpf 都贡献一下,同时可以考虑给 RISC-V 架构也都搞一轮……(逃
补充
这部分只做了解,为了便于阅读和修改 BPF 虚拟机实现代码。关于跨平台,该站点收录了相关的宏定义,非常实用。
Calling Convention
Caller-saved register(又名易失性寄存器AKA volatile registers, or call-clobbered)用于保存不需要在各个调用之间保留的临时数量。因此,如果要在过程调用后恢复该值,则调用方有责任将这些寄存器压入堆栈或将其复制到其他位置。不过,让调用销毁这些寄存器中的临时值是正常的。从被调用方的角度来看,您的函数可以自由覆盖(也就是破坏)这些寄存器,而无需保存/恢复。
Callee-saved register(又称非易失性寄存器AKA non-volatile registers, or call-preserved)用于保存应在每次调用中保留的长寿命值。当调用者进行过程调用时,可以期望这些寄存器在被调用者返回后将保持相同的值,这使被调用者有责任在返回调用者之前保存它们并恢复它们, 还是不要碰它们。
更通俗的理解:
“ 调用者保存”( caller saving )方法:如果采用调用者保存策略,那么在一个调用者调用别的过程时,必须保存调用者所要保存的寄存器,以备调用结束返回后,能够再次访问调用者。 “ 被调用者保存”( callee saving )方法:如果采用被调用者保存策略,那么被调用的过程必须保存它要用的寄存器,保证不会破坏过程调用者的程序执行环境,并在过程调用结束返回时,恢复这些寄存器的内容。
GNU ASM
下面 x86-64 的示例程序,采用的都是 AT&T 语法,也是 GNU 流行的语法,和之前汇编课上的语法略有区别:需要在寄存器前面添加前缀%,例如%eax;在AT&T语法中,第一个是源操作数,第二个是目标操作数。Intel 语法和 AT&T 语法的常见指令格式对比如下

只需要使用 asm 就可以在 C/C++ 下写汇编程序
C
#ifdef __x86_64__
asm volatile (
"mov $0xf0, %rax;"
);
#elif __ARM_ARCH_7__
asm volatile (
"mov r0, #0xf0;"
);
#endif
有一个很有趣的现象是,写 ARM 的汇编指令却不需要遵守类似上面 AT&Y 的语法规则,可以直接按 ARM 官方文档的写法。也有老哥在 StackOverflow 上问了这个问题。解答是:
为啥 GNU Assembler (GAS) 在 x86 上用 AT&T 语法呢?是考虑到了 x86 上 AT&T's 汇编器的可移植性。AT&T 没有使用 Intel 官方的 x86 汇编语法,而是选择了基于他们早期的 68000 和 PDP-11 汇编器创建新的语法。当 x86 支持被添加到了 GNU compiler (GCC) 的时候,它生成的是 AT&T 语法的汇编程序,因为他们用的汇编器就是这样的。
然而没有 AT&T 为 ARM CPU 写的汇编器,当 GNU 开始一直 GCC 和 GAS 到 ARM 目标机器上的时候,没理由继续创建一个新的、移植性差的语法了。于是他们就选用了 ARM 的官方语法。这就意味着你能够查询 ARM 的官方文档,在 GNU 汇编器中使用上面的标准的 ARM 指令。
x86-64
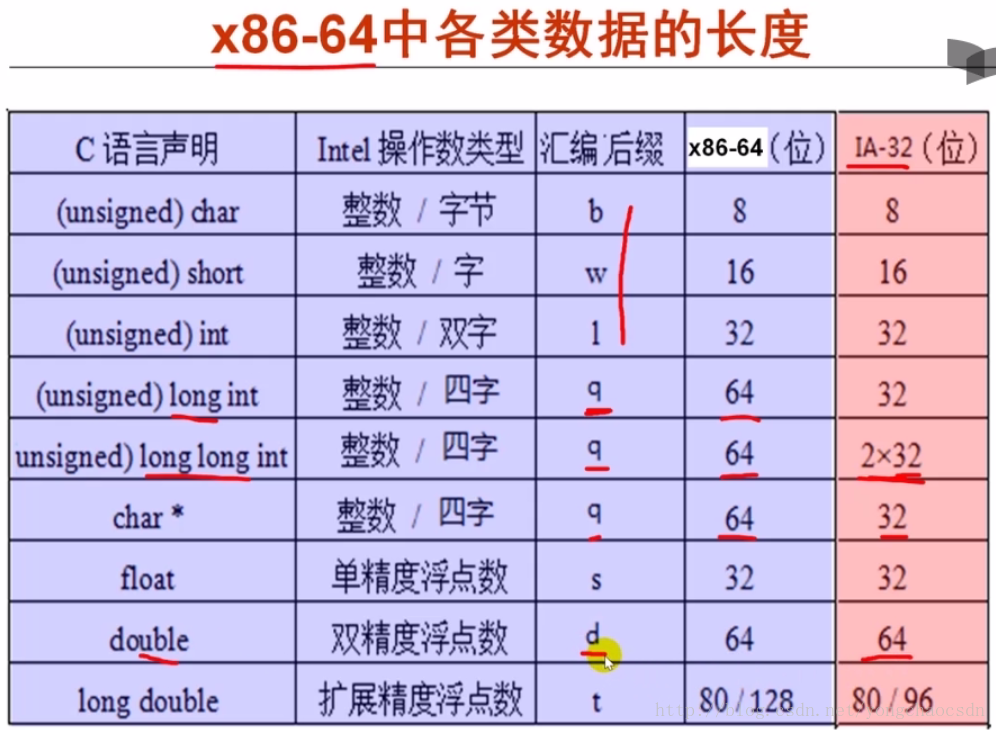
Intel 最初提出的是 IA-64,但是由于不兼容 IA-32(x86-32),销量并不理想。AMD 于是推出了一款兼容 IA-32 的指令,叫 x86-64,干脆取名为 AMD64。x86-64 上不同数据类型的长度,其中 long double 多余的位是为了对齐。
General purpose registers (GPRs) 在 x86-32,x86-64 上分别如下
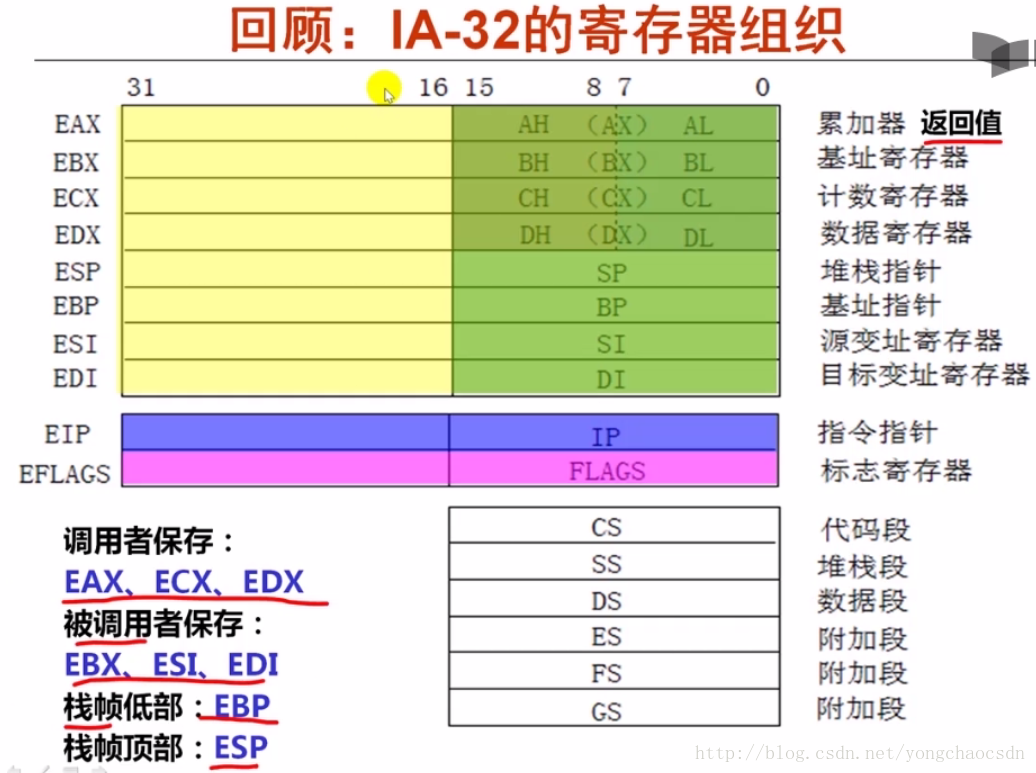
x86-32 扩展了 x86-16 的寄存器,加了字母 E 来标识,低位仍然可以视作 16 位的寄存器。同样的,x86-64 进一步扩展了 x86-32 的寄存器,用 R来标识,如下图

具体的使用方面如下图。可以看到,在名称上需要取低位的时候,旧的架构中存在的寄存器,仍然可以用旧的架构中的名字;新增的寄存器,则通过后缀 Byte (B)、Word (W)、Double Word(DW)来区分。

下面的图阐述了寄存器们具体的功能,同时除了 rsp 和明确标识被调用者保护的 rbx,rbp,r12,r13,r14,r15,其余都是调用者需要保护的寄存器。

下面是一个表达式运算的例子,先进行类型转换,与运算中更长的类型统一位数后再进行计算

函数调用的例子,在 x86-32 中需要用到栈,但是在 x86-64 中可以更简单地直接调用寄存器
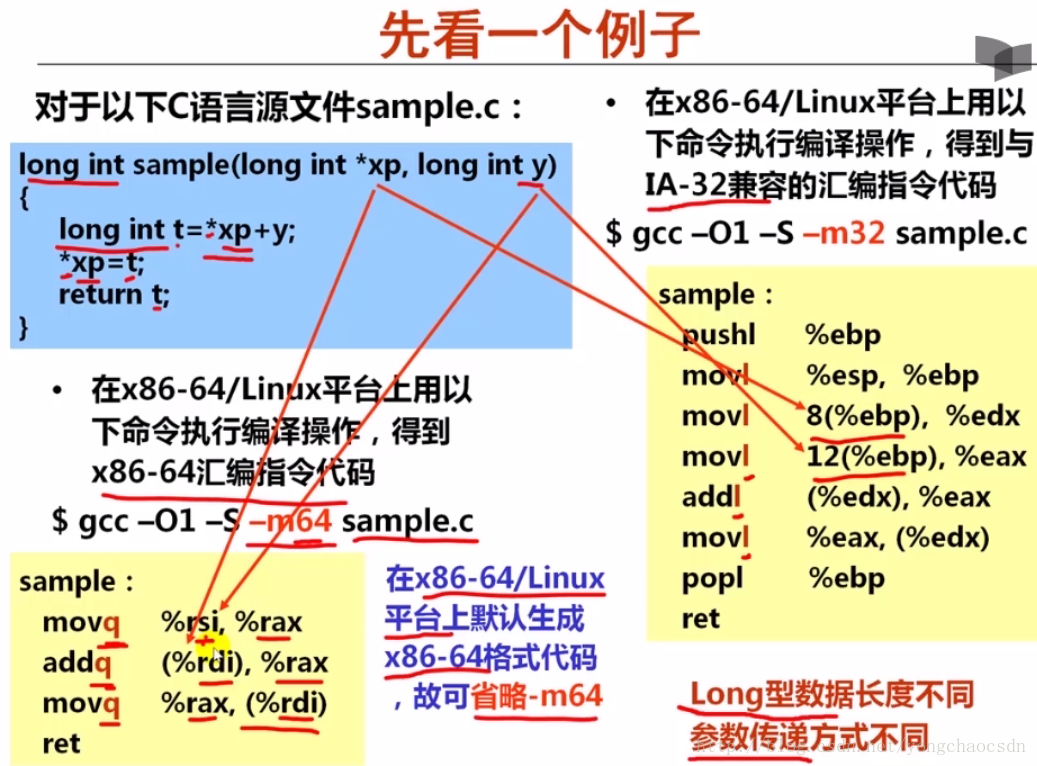
更加详细的过程调用参数传递规范,有下表
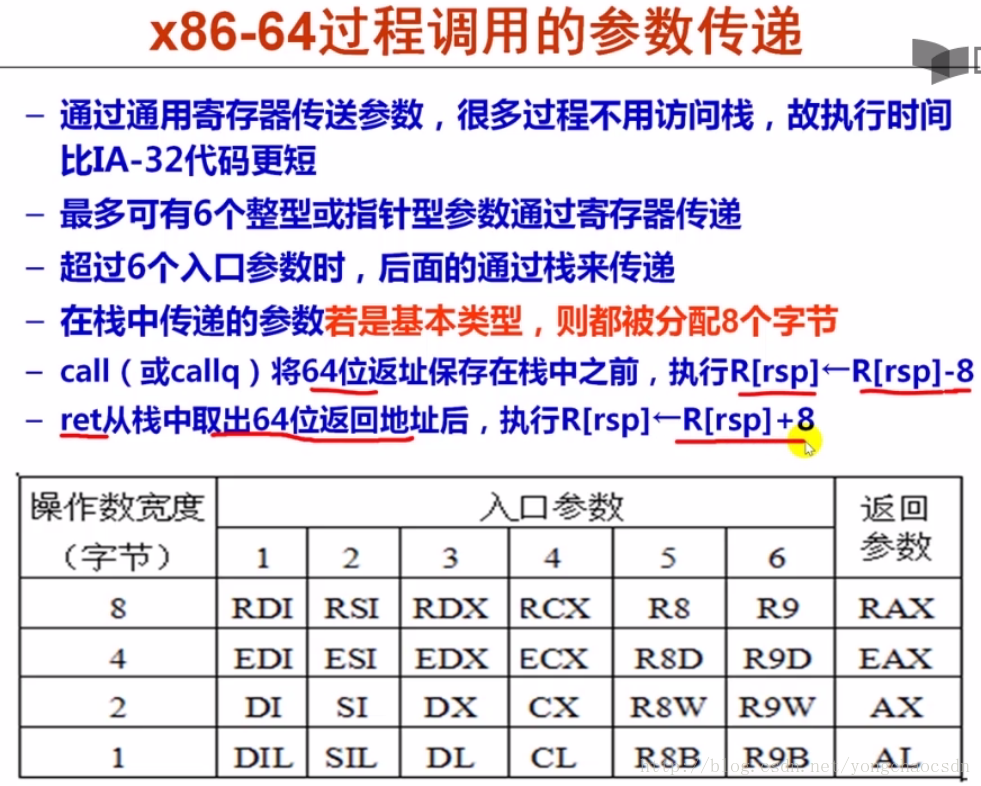
根据上表,一个较为复杂的例子如下

ARMv7-M
如之前笔记所述,ARMv7-M 适用于嵌入式系统等功耗低的场景,只支持Thumb指令集,用于微处理器领域。它的寄存器为 32 位。以 Cortex-M4 为例,它包含了 32 个寄存器,其中 13 个是通用寄存器(GPR),还有一些是具有特殊意义的寄存器。具体而言,GPR 为 R0-R12,R13 是 Stack Pointer(SP),R14 是 Link Register (LR),R15 是 Program Counter(PC),其余都是 Special-purpose Program Status Registers, (xPSR)。
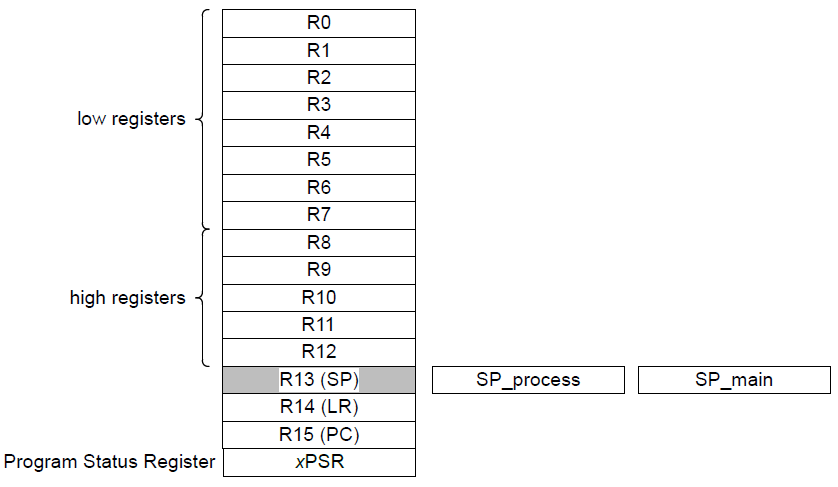
从上图中可以看出通用寄存器分为
- low registers 是 R0 到 R7,所有指令都能使用他们
- high registers 是 R8 到 R12,32 位指令可以使用,都是16位指令不能使用
特殊的寄存器:
- SP:R13 会忽略掉位 [1:0] 的写操作,因此它自动是按 word 对齐的(4个Byte)。处理异常的 Handler 模式下总是使用 SP_main,但是也可以配置 Thread 模式使用 SP_main 或 SP_process。"Thumb" 模式下的 Push/Pop 指令用这个寄存器。
- LR:R14 是链接子程序的寄存器。当执行 Branch and Link (BL) 或 Branch and Link with Exchange (BLX) 指令的时候,LR 接收从 PC 返回的地址。LR 也用来处理异常的返回。在其他时候,也可以把它当做通用寄存器。
- PC:R15 的第 0 位总是0,指令地址都是按 word 或 half-word 为界对齐的。
至于其他 16 个寄存器,一般都是用于系统控制,见Cortex-M4 Manual第四章:System Control。
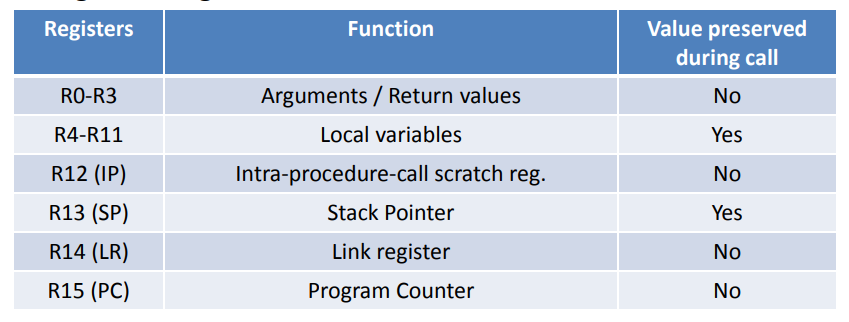
在处理函数调用时,参考 维基百科 和 StackOverflow,32 位 ARM 的 Calling Convention (即 caller-saved 还是 callee-saved)是遵从 AAPCS 第5.1.1 寄存器相关章节。从功能上来讲
- R12:Intra-Procedure-call scratch register,调用者保存
- R4 ~ R11:局部变量,除了 R9 都是被调用者存储的寄存器,R9在某些情况下是特殊寄存器
- R0 ~ R3:传递给子程序的参数和子程序返回的结果,调用者保存
用一张表描述
例子:


Reference
BPF 开发QA:解释了两条bpf相关的内核分支的作用,规定了汇报bug、提交补丁的方法。
Facebook 的 BPF 相关团队成员博客,大部分内容都摘录、翻译自这里。
eBPF-Helpers,ebpf 程序的 API 函数文档,貌似和这里的内容重复。
Cilium 文档 详细讲解了 bpf 和 xdp。
iovisor eBPF spec 列出了 eBPF opcode,项目是 iovisor 总结的系列文档、pre。
架构、指令集相关:
Caller-saved register and Callee-saved register
X86-64指令系统_yongchaocsdn的博客-CSDN博客
ARMv7-M Documentation – Arm Developer